
Images from Unsplash
Disclaimer: This article is my learning note from the courses I took from Kaggle.
Many people tend to say that machine learning models are “black boxes” because they can make good predictions but cannot understand the logic behind those predictions.
In this course, we will learn on methods to extract insights from model:
- What features in the data the model think as the most important?
- How each feature affect the prediction?
So, why do we need model insights? Model insights can be useful in a couple of ways:
Debugging
Given the frequency and potentially disastrous consequences of bugs, debugging is one of the most valuable skills in data science. Understanding the patterns a model is finding will help you identify when those are at odds with your knowledge of the real world, and this is typically the first step in tracking down bugs.
Informing Feature Engineering
Feature engineering is usually the most effective way to improve model accuracy. Feature engineering usually involves repeatedly creating new features using transformations of your raw data or features you have previously created.
Sometimes you can go through this process using nothing but intuition about the underlying topic. But you’ll need more direction when you have 100s of raw features or when you lack background knowledge about the topic you are working on.
Directing Future Data Collection
You have no control over datasets you download online. But many businesses and organizations using data science have opportunities to expand what types of data they collect. Collecting new types of data can be expensive or inconvenient, so they only want to do this if they know it will be worthwhile. Model-based insights give you a good understanding of the value of features you currently have, which will help you reason about what new values may be most helpful.
Informing Human Decision-Making
Some decisions are made automatically by models. Amazon doesn’t have humans (or elves) scurry to decide what to show you whenever you go to their website. But many important decisions are made by humans. For these decisions, insights can be more valuable than predictions.
Building Trust
Many people won’t assume they can trust your model for important decisions without verifying some basic facts. This is a smart precaution given the frequency of data errors. In practice, showing insights that fit their general understanding of the problem will help build trust, even among people with little deep knowledge of data science.
1. Permutation Importance
Permutation importance is calculated after a model has been fitted. Imagine that now, we want to predict a person’s height when they become 20 years old using only data that is available at age 10.

Now, if we randomly shuffle a single column of the validation data but all the other columns remain in place, how would the accuracy of the prediction be affected?

Of course, such an approach would reduce the model accuracy, since the data no longer corresponds to what we can observe in the real world. Model accuracy especially suffers if we shuffle a column that the model relied on heavily for predictions. In this case, shuffling height at age 10 would cause terrible predictions. If we shuffled socks owned instead, the resulting predictions wouldn’t suffer nearly as much.
So, here is what we can do:
- Get a trained model
- Shuffle values in a single column and make prediction from it. Calculate the difference of prediction and target value with a loss function. The performance deterioration is the importance of the variable that we shuffled
- Return to step 2 until all the importance for each column is calculated
1.1 Example
Here is how to calculate the importance with eli5 library:
import eli5
from eli5.sklearn import PermutationImportance
perm = PermutationImportance(my_model, random_state=1).fit(val_X, val_y)
eli5.show_weights(perm, feature_names = val_X.columns.tolist())
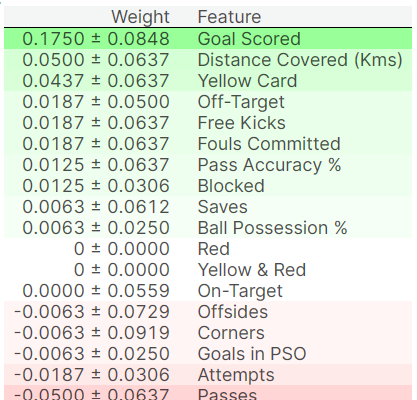
From the above figure, the values towards the top is the most important features. The first number in each row shows how much the model performance decreased with a random shuffling. There is some randomness to the exact performance change from a shuffling a column. We measure the amount of randomness in our permutation importance calculation by repeating the process with multiple shuffles. The number after the ± measures how performance varied from one-reshuffling to the next.
You’ll occasionally see negative values for permutation importance. In those cases, the predictions on the shuffled (or noisy) data happened to be more accurate than the real data. This happens when the feature didn’t matter (should have had an importance close to 0), but random chance caused the predictions on shuffled data to be more accurate. This is more common with small datasets, like the one in this example, because there is more room for luck/chance.
2. Partial Plots
Similar to permutation importance, partial dependence plots are calculated after a model has been fit. To see how partial plots separate out the effect of each feature, we start by considering a single row of data. For example, that row of data might represent a team that had the ball 50% of the time, made 100 passes, took 10 shots and scored 1 goal.
We will use the fitted model to predict our outcome (probability their player won “man of the match”). But we repeatedly alter the value for one variable to make a series of predictions. We could predict the outcome if the team had the ball only 40% of the time. We then predict with them having the ball 50% of the time. Then predict again for 60%. And so on. We trace out predicted outcomes (on the vertical axis) as we move from small values of ball possession to large values (on the horizontal axis).
2.1 Example
Let’s get a decision tree from the model:
from sklearn import tree
import graphviz
tree_graph = tree.export_graphviz(tree_model, out_file=None, feature_names=feature_names)
graphviz.Source(tree_graph)
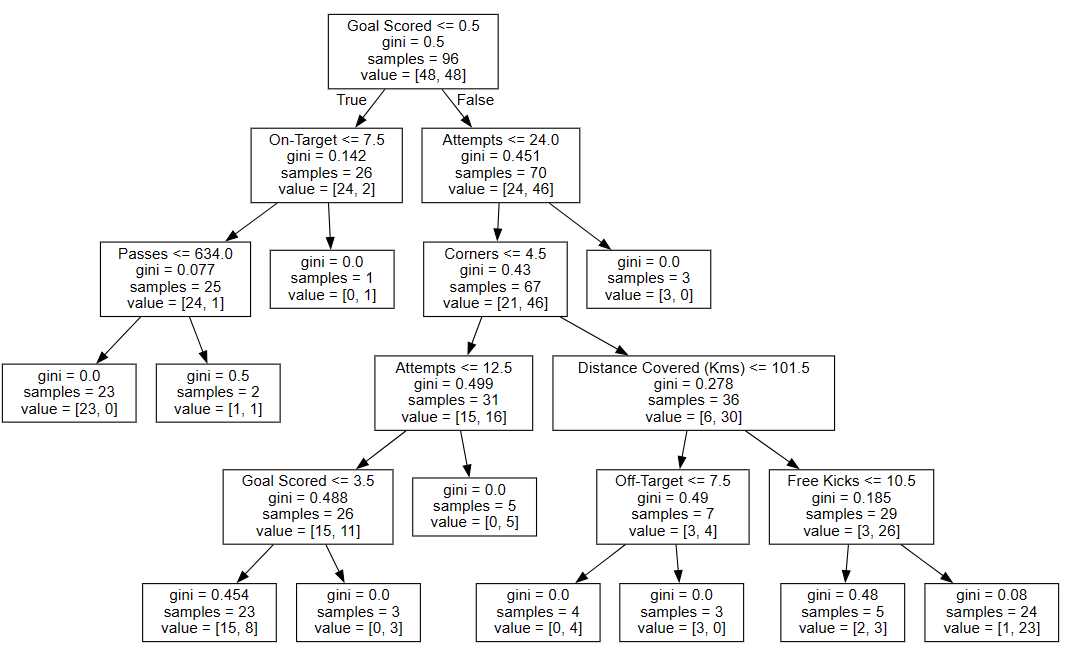
Produce a partial dependence plot:
from matplotlib import pyplot as plt
from sklearn.inspection import PartialDependenceDisplay
# Create and plot the data
disp1 = PartialDependenceDisplay.from_estimator(tree_model, val_X, ['Goal Scored'])
plt.show()

The y-axis is interpreted as change in the prediction from what it would be predicted at the baseline or leftmost value.
From this particular graph, we see that scoring a goal substantially increases your chances of winning “Man of The Match.” But extra goals beyond that appear to have little impact on predictions.
feature_to_plot = 'Distance Covered (Kms)'
disp2 = PartialDependenceDisplay.from_estimator(tree_model, val_X, [feature_to_plot])
plt.show()

This graph seems too simple to represent reality. But that’s because the model is so simple. You should be able to see from the decision tree above that this is representing exactly the model’s structure.
# Build Random Forest model
rf_model = RandomForestClassifier(random_state=0).fit(train_X, train_y)
disp3 = PartialDependenceDisplay.from_estimator(rf_model, val_X, [feature_to_plot])
plt.show()

This model thinks you are more likely to win Man of the Match if your players run a total of 100km over the course of the game. Though running much more causes lower predictions.
In general, the smooth shape of this curve seems more plausible than the step function from the Decision Tree model. Though this dataset is small enough that we would be careful in how we interpret any model.
2.2 2D Partial Dependence Plots
We will use the same datasets as of above:
fig, ax = plt.subplots(figsize=(8, 6))
f_names = [('Goal Scored', 'Distance Covered (Kms)')]
# Similar to previous PDP plot except we use tuple of features instead of single feature
disp4 = PartialDependenceDisplay.from_estimator(tree_model, val_X, f_names, ax=ax)
plt.show()

From the plot above, we see the highest predictions when a team scores at least 1 goal and they run a total distance close to 100km. If they score 0 goals, distance covered doesn’t matter. Can you see this by tracing through the decision tree with 0 goals?
But distance can impact predictions if they score goals. Make sure you can see this from the 2D partial dependence plot.
3. SHAP Value
SHAP or SHapley Additive exPlanations is used to break down a prediction t0 show the impact of each feature. It interprets the impact of having a certain value for a given feature in comparison to the prediction we would make if that feature took some baseline value.
For example, consider the Man of the Match award example for previous section, we could ask questions like how much prediction driven by the fact that the team scored 3 goals?
But for each team, they are many features, so if we answer for the number of goals, we could repeat the process for other features too. SHAP values of all features sum up to explain why my prediction was different from the baseline.
sum(SHAP values for all features) = pred_for_team - pred_for_baseline_values

To interpret the graph:
We predicted 0.7, whereas the base_value is 0.4979. Feature values causing increased predictions are in pink, and their visual size shows the magnitude of the feature’s effect. Feature values decreasing the prediction are in blue. The biggest impact comes from Goal Scored being 2. Though the ball possession value has a meaningful effect decreasing the prediction.
If you subtract the length of the blue bars from the length of the pink bars, it equals the distance from the base value to the output.
How to Do That in Code
Let’s get the model ready:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
data = pd.read_csv('../input/fifa-2018-match-statistics/FIFA 2018 Statistics.csv')
y = (data['Man of the Match'] == "Yes") # Convert from string "Yes"/"No" to binary
feature_names = [i for i in data.columns if data[i].dtype in [np.int64, np.int64]]
X = data[feature_names]
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1)
my_model = RandomForestClassifier(random_state=0).fit(train_X, train_y)
We will look for SHAP value for a single row of the dataset. Let’s check on the raw prediction first:
row_to_show = 5
data_for_prediction = val_X.iloc[row_to_show] # use 1 row of data here. Could use multiple rows if desired
data_for_prediction_array = data_for_prediction.values.reshape(1, -1)
my_model.predict_proba(data_for_prediction_array)
The output is array([[0.29, 0.71]]), the team is 70% likely to have a player win the award
import shap # package used to calculate Shap values
# Create object that can calculate shap values
explainer = shap.TreeExplainer(my_model)
# Calculate Shap values
shap_values = explainer.shap_values(data_for_prediction)
shap.initjs()
shap.force_plot(explainer.expected_value[1], shap_values[1], data_for_prediction)
The shap_values object above is a list with two arrays. The first array is the SHAP values for a negative outcome (don’t win the award), and the second array is the list of SHAP values for the positive outcome (wins the award). We typically think about predictions in terms of the prediction of a positive outcome, so we’ll pull out SHAP values for positive outcomes (pulling out shap_values[1]).

Of course, SHAP package also has explainers for every type of model:
shap.DeepExplainerworks with Deep Learning models.shap.KernelExplainerworks with all models, though it is slower than other Explainers and it offers an approximation rather than exact Shap values.
4. Advanced Uses of SHAP Value
Shap values show how much a given feature changed our prediction (compared to if we made that prediction at some baseline value of that feature).
Consider the equation:
y = 4 * x1 + 2 * x2
If x1 takes the value 2, instead of a baseline value of 0, then our SHAP value for x1 would be 8 (from 4 times 2).
These are harder to calculate with the sophisticated models we use in practice. But through some algorithmic cleverness, Shap values allow us to decompose any prediction into the sum of effects of each feature value, yielding a graph like this:

In addition to this nice breakdown for each prediction, the Shap library offers great visualizations of groups of Shap values. We will focus on two of these visualizations. These visualizations have conceptual similarities to permutation importance and partial dependence plots
SHAP summary plots give us a birds-eye view of feature importance and what is driving it. We’ll walk through an example plot for the soccer data:
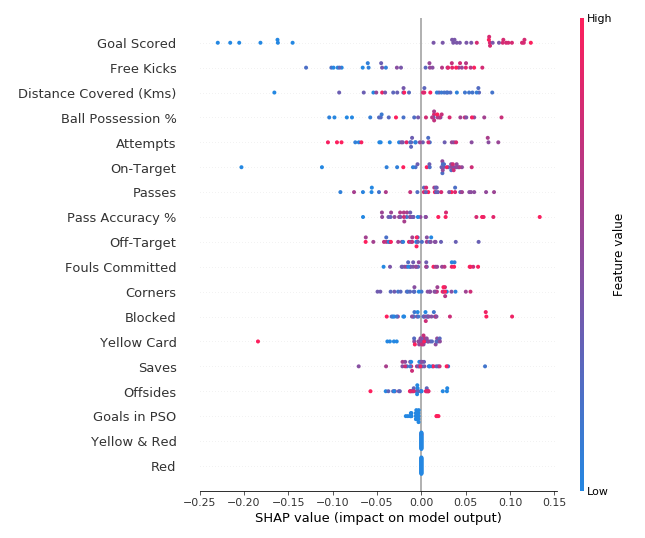
This plot is made of many dots. Each dot has three characteristics:
- Vertical location shows what feature it is depicting
- Color shows whether that feature was high or low for that row of the dataset
- Horizontal location shows whether the effect of that value caused a higher or lower prediction.
Some things you should be able to easily pick out:
- The model ignored the Red and Yellow & Red features.
- Usually Yellow Card doesn’t affect the prediction, but there is an extreme case where a high value caused a much lower prediction.
- High values of Goal scored caused higher predictions, and low values caused low predictions
How to Do That in Code
Get the data and model ready:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
data = pd.read_csv('../input/fifa-2018-match-statistics/FIFA 2018 Statistics.csv')
y = (data['Man of the Match'] == "Yes") # Convert from string "Yes"/"No" to binary
feature_names = [i for i in data.columns if data[i].dtype in [np.int64, np.int64]]
X = data[feature_names]
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1)
my_model = RandomForestClassifier(random_state=0).fit(train_X, train_y)
Let’s get a SHAP summary plot:
import shap # package used to calculate Shap values
# Create object that can calculate shap values
explainer = shap.TreeExplainer(my_model)
# calculate shap values. This is what we will plot.
# Calculate shap_values for all of val_X rather than a single row, to have more data for plot.
shap_values = explainer.shap_values(val_X)
# Make plot. Index of [1] is explained in text below.
shap.summary_plot(shap_values[1], val_X)

The code isn’t too complex. But there are a few caveats.
- When plotting, we call
shap_values[1]. For classification problems, there is a separate array of SHAP values for each possible outcome. In this case, we index in to get the SHAP values for the prediction of “True”. - Calculating SHAP values can be slow. It isn’t a problem here, because this dataset is small. But you’ll want to be careful when running these to plot with reasonably sized datasets. The exception is when using an xgboost model, which SHAP has some optimizations for and which is thus much faster.
SHAP Dependence Contributions Plots
For SHAP dependence contribution plots provide a similar insight to partial dependence plot’s, but they add a lot more detail.
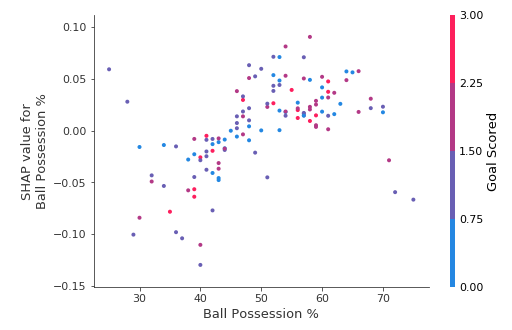
Each dot represents a row of the data. The horizontal location is the actual value from the dataset, and the vertical location shows what having that value did to the prediction. The fact this slopes upward says that the more you possess the ball, the higher the model’s prediction is for winning the Man of the Match award.
The spread suggests that other features must interact with Ball Possession %. For example, here we have highlighted two points with similar ball possession values. That value caused one prediction to increase, and it caused the other prediction to decrease.
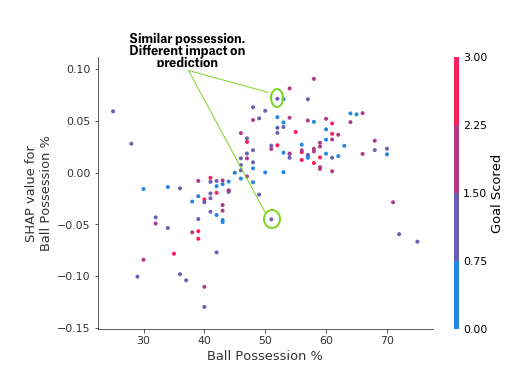
For comparison, a simple linear regression would produce plots that are perfect lines, without this spread.
This suggests we delve into the interactions, and the plots include color coding to help do that. While the primary trend is upward, you can visually inspect whether that varies by dot color.
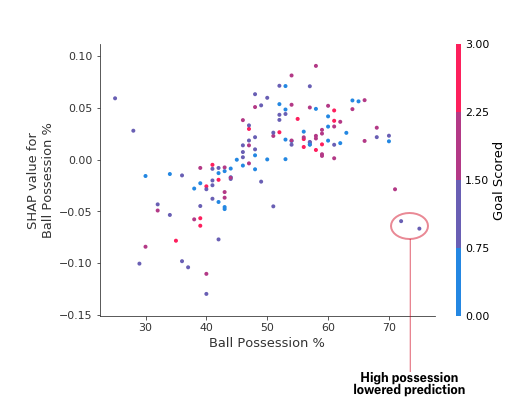
These two points stand out spatially as being far away from the upward trend. They are both colored purple, indicating the team scored one goal. You can interpret this to say In general, having the ball increases a team’s chance of having their player win the award. But if they only score one goal, that trend reverses and the award judges may penalize them for having the ball so much if they score that little.
How to Do That in Code
import shap # package used to calculate Shap values
# Create object that can calculate shap values
explainer = shap.TreeExplainer(my_model)
# calculate shap values. This is what we will plot.
shap_values = explainer.shap_values(X)
# make plot.
shap.dependence_plot('Ball Possession %', shap_values[1], X, interaction_index="Goal Scored")

If you don’t supply an argument for interaction_index, Shapley uses some logic to pick one that may be interesting!